丑牛迷你采集器是一款基于Java Swing开发的专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从 网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站
JAVACOO-CRAWLER采用的是模块化设计,各个模块由一个控制器类(CrawlController类)来协调工作,控制器就是爬虫的核心。
CrawlController类是整个爬虫的总控制者,控制整个采集工作的的起点,决定采集任务的开始,暂停,继续,结束。
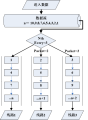
CrawlController类主要包括以下模块:分别是爬虫的配置参数,字符集帮助类, HttpCilent对象,HTML解析器包装类,爬虫边界控制器,爬虫线程控制器,处理器链,过滤器工厂,整体架构图如下:

输入图片说明
爬虫配置参数(CrawlScope): 存储当前爬虫的配置信息,如采集页面编码,采集过滤器列表,采集种子列表,爬虫持久对象实现类等,CrawlController根据配置参数来初始化其他模块。
字符集帮助类(CharsetHandler):根据当前爬虫配置参数中字符集配置来初始化,备整个采集过程使用。
HttpCilent对象(HttpClient):根据当前爬虫配置参数初始化HttpClient对象,如:设置代理,设置连接/请求超时,最大连接数等。
HTML解析器包装类(HtmlParserWrapper):对HtmlParser解析器进行特殊化封装,以便满足采集任务的需要。
爬虫边界控制器(Frontier):主要是加载爬行种子链接并根据加载的种子链接初始化任务队列,以备线程控制器(ProcessorManager)开启的任务执行线程(ProcessorThread)使用。
爬虫线程控制器(ProcessorManager):主要是控制任务执行线程数量,开启指定数目的任务执行线程执行任务。
过滤器工厂(FilterFactory):注册当前爬虫配置参数中过滤器集合,供采集任务查询使用。
主机缓存(HostCache):缓存HttpHost对象。
处理器链(ProcessorChainList):默认构建了5中处理链,依次是,预取链,提取链,抽取链,写链,提交链,在任务处理线程中将使用。
预取链:主要是做一些准备工作,例如,对处理进行延迟和重新处理,否决随后的操作。
提取链:主要是下载网页,进行 DNS 转换,填写请求和响应表单。
抽取链 : 当提取完成时 , 抽取感兴趣的 HTML 和 JavaScript 等 。
写链:存储抓取结果,可以在这一步直接做全文索引。
提交链:做和此 URL 相关操作的最后处理。
系统登录界面

输入图片说明
系统启动界面

输入图片说明
系统主界面
(1)我的丑牛:系统信息,插件信息,内存监控,以及任务监控

我的丑牛
(2)采集配置:采集相关的基础配置,包括远程数据库配置,FTP配置,自定义数据配置

采集配置
(3)数据采集:对采集过程统一管理,包括采集公共参数设置,采集规则列表,采集历史列表,采集内容列表

数据采集
(4)任务监控:包括采集任务监控,入库任务监控,图片处理任务监控,上传任务监控

任务监控
(5)定时任务:定时执行采集任务

定时任务
(6)实用工具:包括图片处理

实用工具
https://gitee.com/javacoo/CowSwing
链接:https://pan.baidu.com/s/1OMWnlNIVQYljn9cAC2pHYw
提取码:l50r
2023-12-13T11:46:19
2023-12-13T11:48:22
2024-01-02T09:07:42

2024-01-02T09:07:20
2024-01-02T09:06:50

2024-01-02T09:06:26
2024-01-02T09:06:01
2024-01-02T09:05:20
2024-01-02T09:04:49
2024-01-02T09:04:17
